The goal of stemming is to reduce derived forms of a word to something that could be a root form. For example a possible stem of “lighting” or “lighted” is “light”. This is generally done by applying a list of fairly simple rules to a word, possibly recursively, until the algorithm is done and a root form is returned.
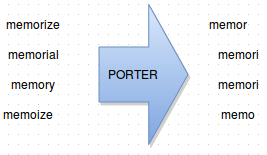
There are several reasons for stemming a word. The primary concern is to increase the recall of a search index. The most basic case here is the handling of plurals; a user generally expects the same result when searching for “nachos dip” as when they search for “nacho dip.” But recall can be improved in other cases as well, for example a user searching for “democracy” is probably also interested in results for “democratic”. Another concern is reducing index size; this can increase search speed and reduce storage usage (both of these are good for reducing costs).
But stemming is an inexact science. Most stemming algorithms don’t attempt to extract morphological information about the word to determine the stem, so unrelated terms can be conflated. While working at an old employer, one of my colleagues found an interesting issue caused by imprecise stemming. A client was complaining that a search for “rug” was matching most of the items in their catalog, even though most of them didn’t have anything to do with rugs. It turns out that, as an outdoor gear supplier, the client had the term “rugged” in most of the product descriptions on their site. The solution to this issue was to tweak the stemmer used for this index.
This example shows that, while stemming can improve recall, it reduces precision. As software developers, we are used to making these trade offs. The effectiveness of a given stemming method will vary depending on your corpus. So it’s important to learn the ins and outs of your stemmers, and learn when to tweak them.
I found an interesting comparison of stemmer results in an elastic search user forum.
| Original |
|---|